With respect to phonemes, we hear a particular sound, such as “t” across a range of acoustic stimuli. Then at a particular point along an acoustic dimension, our perception shifts, and we hear the sound as a different phoneme (e.g., “d”). This is illustrated nicely with a phenomenon called voice-onset time. Voice-onset time refers to the production of certain consonants (called stop consonants) in which there is a difference between the first sounds of the phoneme and the movement of the vocal cords. The movement of the vocal cords is called voicing. Consider the difference between the phonemes “t” and “d.” The phonemes “t” and “d” are similar with respect to the position of the mouth, but “t” is voiceless, and “d” is voiced. That is, the vocal cords do not vibrate when we say “t” but they do when we say “d.” In the phrase, “ta,” our vocal cords vibrate 74 milliseconds after the burst of sound for the “t,” corresponding to the “a” part of the sound. However, when we say the voiced “da,” there is vocal cord vibration within 5 milliseconds of the start of sound.
On the Illustrations/Sounds tab you can see sound spectrograms for "da" and "ta" and see the delay in the vocal cords for the "ta" relative to the "da". You can also play the sounds. Can you hear this delay?
Voicing is seein in sound spectrograms as strong regular vertical striations. Notice how on the "ta", the strations start much later than on the "da".
| 'Da' | 'Ta' |
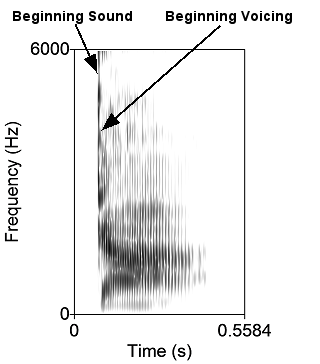 |
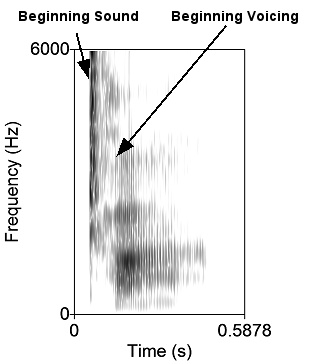 |
| Play | Play |